#error code 403
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
(Roblox errors can be irritating. By using these step-by-step guides, you can hopefully fix the problem.)
Roblox is one of the popular games available for Android, Switch, PC, and more, developed by the Roblox corporation. Still, the platform has some fair issues that need to be resolved. You often encounter error code 403, which may irritate you sometimes. This error happens when you can’t connect to the Roblox’s servers. In this article, we will explain the cause of this error and the ways to fix it.
Read More - https://monoscoop.com/how-to-fix-error-code-403-roblox/
0 notes
Text
Reminder that you can submit your own ships in the inbox to poll them! :D
Requested by the randomized anon
#we called it error 403 bc in http status codes it essentially means “the server knows what you want but it won't let you have it” stuff#aka the spectre knows what jane doe wants but it won't let her find her husband so easily#also it's one digit away from meaning “not found”#anyways#ship polls#forsaken#forsaken roblox#roblox forsaken#john doe forsaken#jane doe forsaken#error 403#john doe x jane doe forsaken#mod c00lkidd‼️‼️
40 notes
·
View notes
Text
hey milgram fans. i wanted to talk about the apartment number of amane’s family.

you might be thinking, ‘what could be so special about this? it’s just an apartment number.’
well, considering that even in yuno’s first trial video that she had a symbol on her bag that referred to abortion, meaning that milgram doesn’t skimp on tiny details, i wanted to introduce you all to ‘goroawase’; japanese word play revolving around the pronunciation of numbers.
i tried brute forcing all potential pronunciations of 4, 0, and 3, in that order… and I think I got a hit that might be useful.
4 can be pronounced ‘Shi,’ homonymous for ‘death,’ 0 can be pronounced ‘ma,’ and 3 can be pronounced ‘za.’
死マザー (Shimazaa), using the English loan word for ‘Mother,’ can be equated to ‘Dead/Death (of) Mother’
and considering how we know that her father is away, and the hand that held the taser against amane looked feminine…

i think we may be able to take that as a clue it may have been her mother she killed.
also, side note: another notable ‘403’ is that it’s an error code. may also have some meaning.

385 notes
·
View notes
Text
Kowloon Generic Romance Episode 10 Review - 403 Forbidden
Now that the episode count is at the double digits, I do feel as if the mysteries are on the verge of being solved. Kujirai-B’s glasses seem to be a clue to the mysteries surrounding the original and Kowloon. I also feel like Xiaohei’s existence might also be a major clue. I do wonder how everything will wrap up in just three more episodes…

The mysteries of Kowloon keep increasing as Kujirai’s glasses suddenly show images of her original’s memories. That’s odd. Her glasses never did that before, so why are they doing it now? Some of her memories show her images of an area that’s off-limits due to how dangerous it could be. Even in the original Second Kowloon, the area was known for being shady and dangerous to the point that Kudo banned Kujirai-B from going there again and it retained with the generic. When she went there with Yaomay, the talisman-riddled walls are of intrigue. When Kujirai peels one off, the back reads ‘403 Forbidden’, hinting that phantom world is a simulation. When she decides to go around to peel off all the talismans she can find, a few are blank and some have that same error code. However, one has 202 Accepted on the back and then the last one she finds before the episode ends is “Don’t find it anymore.” I feel like Generic Terra is trying to block her from snooping around too much—that’s why people who eat the food in this world lose their memories like how Yaomay did.






Kowloon is such a mystery. It’s not even erasing the generic Xiaohei despite the original roaming around in its walls. Is it because the Generic and the Original are physically different? Xiaohei is an unusual case where his current and his past self are extremely different. Is it because he used to live in Kowloon in the form of his younger self that the system counts the original as a different person? This means that Generic Terra isn’t completely perfect if it’s unable to detect that original Xiaohei and generic Xiaohei are the same… I think that could be its major weakness.


There also seems to be some sort of romance blooming with Xiaohei and Yaomay, but who knows if it will get anywhere given that Xiaohei is conflicted on whether he should do as Yulong says or if he should continue his mission as a spy. Killing Generic Kujirai can also mean the end of a friendship with Yaomay, after all. Speaking of Yaomay, I do like that she’s essentially the key to solving everything in a way as she’s the only person in the story with no real connection to Kowloon other than stumbling upon it one day. Eating the chocolate that Yulong gave to her during her trip to Hong Kong does seem like eating food outside of Kowloon regains people’s memories—either that or Yulong is just some crazy scientist that knows how to counter Kowloon mindfuckery in the form of candy.

I can’t wait to see what the epic conclusion to this anime will be like. This is one of the shows I enjoy watching every week because it just gets me thinking. It also makes me anticipate every Saturday. Let me know your thoughts on this episode!

#kowloon generic romance#Reiko kujirai#Hajime kudo#Kujirai b#yaomay#tao gwen#xiaohei#yulong#review#anime#anime review#ecargmura#arum journal
6 notes
·
View notes
Text

a terra incognita character introduction
cast: jake ✗ fem.reader
synopsis: as the world entered the middle of the 21st century, many things have changed for the better or for worse in the newly united korea peninsula: the preparation for the succession of the new conglomerates of the past decade, the uprising of deviant androids, and the new layer of life shield by walls of codes. in the middle of it, two beings are trying to understand each other and the situation of the world they live in; an unknown territory
genre: cyberpunk, cyber noir, psychological thriller, science fiction, dystopian future, politics and philosophies regarding artificial intelligence and humanity, romance, drama, angst, mature content (war and revolution, explicit smut)
based on: video game cyberpunk 2077 (2020) and detroit: become human (2018), anime serial experiments lain (1998), and tv show succession (2018-2023)
masterlist

from north seoul
(y/n)
name: (l/n) (y/n)
aliases: Error 403: Forbidden
age: 20
species: human
gender: female
family: mom (deceased), dad (deceased), leon (uncle; alive), mara (aunt; deceased), kai (cousin; alive), bahiyyih (cousin; alive)
affiliation: the rebellion, deviant androids
backstory: Error 403: Forbidden
leon
name: (l/n) leon (oc)
aliases: the mechanic
age: 49
species: human
gender: male
family: mara (wife; deceased), kai (son; alive), bahiyyih (daughter; alive), (y/n)'s dad (brother; deceased), (y/n)'s mom (sister-in-law; deceased), (y/n) (niece; alive)
affiliation: deviant androids
backstory: a mechanic specializing in electronics and automotive, he changes his ways after the family incident of 2035 and is given the responsibility to take care of his niece, (y/n). he adopted two deviant androids, kai and bahiyyih, and now specializes in android repairs and modification
kai
name: (l/n) kai (portrayed by txt's hueningkai)
aliases: HG200 #202 448 140
species: android (HG200)
gender: male
family: leon (father; alive), mara (mother; deceased), bahiyyih (sister; alive), (y/n)'s dad (uncle; deceased), (y/n)'s mom (aunt; deceased), (y/n) (cousin; alive)
affiliation: the rebellion, deviant androids
backstory: dubbed the "dream brother", HG200 is part of the HG series known as the "siblings series". kai, a name he chose after being deviant, used to be a part of a family of abusive parents and their daughter who has autism with the android who is now bahiyyih. by defending the daughter from ongoing attacks, kai deviates from his original path then were scrap to the junkyard, being saved and adopted by leon where they searched for bahiyyih
bahiyyih
name: (l/n) bahiyyih (portrayed by kep1er's huening bahiyyih)
aliases: HG400 #462 777 207
species: android (HG400)
gender: female
family: leon (father; alive), mara (mother; deceased), kai (brother; alive), (y/n)'s dad (uncle; deceased), (y/n)'s mom (aunt; deceased), (y/n) (cousin; alive)
affiliation: the rebellion, deviant androids
backstory: dubbed the "dream sister", HG400 is part of the HG series known as the "siblings series". bahiyyih, a name she kept after how much she liked the meaning, used to be a part of a family of abusive parents and their daughter who has autism with the android who is now kai. by helping said daughter from abuse by alerting emergency services, bahiyyih deviates from her original path and escaped to live in an abandoned building before being saved and adopted by leon with kai

taglist: @raeyunshm @endzii23 @fluffyywoo @camipendragon @hiqhkey @wccycc @cha0thicpisces @y4wnjunz @yeehawnana @beansworldsstuff @kimipxl @blurryriki @reallysmolrenjun @frukkoneeeeg
© writingmochi on tumblr, 2021-2025. all rights reserved
#enhypen imagines#enhypen smut#enhypen x reader#enhypen scenarios#enhypen angst#enhypen fanfiction#jake x reader#rsc: t.i.#cr: jake#cs: enhypen#sc: regina
42 notes
·
View notes
Text
EA Confirms New The Sims 4 Patch on February 27th, Shares “Laundry List”
On Wednesday, February 14th, EA shared a new Laundry List with bug fixes coming to The Sims 4, and also confirms the date for the next patch: February 27th.
These lists are usually shared within a week from a game update, so it’s uncommon that we get confirmation, for the bug fixes and also for the date of the patch, this early. Advertisement
Read their blog post below.
Sul Sul Simmers!
Welcome to this month’s Laundry List, where we share a list of the top community concerns we’re currently investigating and hope to resolve in an upcoming patch.
This is only a list of topics from AnswersHQ with upcoming fixes; there are more topics reported by players that are not listed and are still being worked on. This list is based on reports by players on Answers HQ and helps us continue our work on improving the user experience on a regular basis.
Please note that some topics can be tricky and may require an extended investigation on our end, so even though we are actively reviewing, it’s not a guarantee that we’ll have an immediate fix in the upcoming patch.
Here’s the list of the community concerns we’re investigating and aiming to resolve in the next patch:
Holidays Only Appearing for Three Sims in Household
[CONSOLE] Unable to toggle wall tile placement type between room and single when using controller
Customer Service NPCs Don’t Spawn on Community Lots
Stuck on Residential Rental Lot type
Sims eating prepped ingredients as ‘eat leftovers’
Waffle Maker and Pizza Oven cause constant fires
Vegetarian: Plain Waffles give Violating Principals moodlets
Sims get stuck cooking/eating
Off-grid fridges drain power, can’t turn off utility usage
Save Error : 403:8e5010b7
Error code: 102/122:a0adad34
Can’t fish in winter
Nasi lemak looks nothing like real life dish
Reward Trait still available after purchase
Hoodie Makes Sim’s Eyes Bigger
Thank you for all your patience and valuable help in reporting! Please continue sharing with us any issues you’re experiencing on Answers HQ.
We’ll continue to check in, and together we can make this game the best it can be.
Happy Simming!
15 notes
·
View notes
Text
How to Prevent Unvalidated Redirects and Forwards in Laravel
Introduction
When developing a Laravel application, security should be a top priority. One of the most common vulnerabilities that can put your users at risk is unvalidated redirects and forwards. These vulnerabilities occur when a user is redirected or forwarded to an untrusted URL without proper validation, which can be exploited by attackers to conduct phishing, session fixation, or other malicious activities.

In this blog post, we'll discuss how to identify and prevent unvalidated redirects and forwards in your Laravel applications, including practical coding examples and tips to enhance the security of your website.
What Are Unvalidated Redirects and Forwards?
An unvalidated redirect occurs when a user is sent to a URL that isn't properly checked for trustworthiness. For example, an attacker may trick a user into clicking a link that redirects them to a malicious site.
Similarly, unvalidated forwards happen when the application forwards a user to another resource without proper validation. Attackers can exploit this to bypass security checks or perform unauthorized actions.
Why Are They Dangerous?
Both unvalidated redirects and forwards can be exploited by attackers for various malicious purposes, including:
Phishing attacks: Redirecting users to fake websites to steal their personal information.
Session hijacking: Redirecting users to a page that steals their session data.
Malicious data exposure: Forwards to unauthorized resources.
How to Prevent Unvalidated Redirects and Forwards in Laravel
1. Use Laravel's Built-in Validation for Redirects
One of the simplest ways to avoid these vulnerabilities is to validate URLs before redirecting users. Laravel has a built-in url() method to ensure that the redirect URL is valid and within the allowed domain.
Here’s how you can implement a secure redirect:
use Illuminate\Support\Facades\Redirect; public function redirectToInternalPage($path) { $validPaths = ['/home', '/dashboard', '/profile']; // Allowed paths if (in_array($path, $validPaths)) { return Redirect::to($path); } else { return abort(403, 'Unauthorized redirect.'); } }
This approach ensures that users can only be redirected to predefined paths within your application.
2. Validate External Redirects
If your application needs to redirect users to external URLs, ensure that the redirect destination is trusted. A basic way to achieve this is by checking if the destination URL belongs to a trusted domain:
use Illuminate\Support\Facades\Redirect; use Illuminate\Support\Str; public function redirectToExternalSite($url) { $trustedDomains = ['trustedsite.com', 'anothertrusted.com']; $host = parse_url($url, PHP_URL_HOST); if (in_array($host, $trustedDomains)) { return Redirect::to($url); } else { return abort(403, 'Untrusted redirect destination.'); } }
This will prevent users from being redirected to malicious websites, as the app only allows URLs from trusted domains.
3. Implement URL Whitelisting
Another preventive measure is to implement URL whitelisting. This approach limits the URLs that users can be redirected to, ensuring that they are only sent to trusted destinations.
public function validateRedirect($url) { $whitelistedUrls = ['https://example.com', 'https://secure.com']; if (in_array($url, $whitelistedUrls)) { return Redirect::to($url); } else { return redirect('/home')->with('error', 'Invalid redirect attempt.'); } }
4. Use Redirect::secure() for HTTPS Redirects
To avoid redirection to unsecure HTTP links, always use secure redirects. You can ensure that the user is redirected to a secure HTTPS URL by using Redirect::secure():
return Redirect::secure('/dashboard');
This method forces the redirect to be on an HTTPS connection, enhancing the security of your application.
Preventing Vulnerabilities with Tools
It’s essential to regularly assess your website’s security. For that, you can use our Free Website Security Scanner tool to identify vulnerabilities like unvalidated redirects and forwards.
Visit our tool to get started. Below is a screenshot of the tool's homepage for your reference.

Additionally, after running a scan, you will receive a detailed vulnerability assessment report to check Website Vulnerability, helping you pinpoint areas that need attention.

Conclusion
Unvalidated redirects and forwards are serious security vulnerabilities that can jeopardize your Laravel application. By following the methods outlined in this post, you can secure your application and protect your users from phishing, session fixation, and other malicious activities.
Remember to keep your Laravel application up to date and utilize our free tool for Website Security tests to conduct regular assessments and stay ahead of potential threats.
For more tips and tutorials on securing your Laravel application, visit our blog at Pentest Testing Corp Blog.
2 notes
·
View notes
Text
HxH and HTTP Status Codes
The HTTP 403, 404, and 405 references in the Hunter Exam (as foreshadowing or character-summaries) is so sickening, but at the same time it's hard to deny that Togashi probably was referencing them, considering that the manga came out in 1998 while HTTP codes were a thing since 1992-1993 (and he spent a whole page explaining what the internet and computers were). It could definitely be a coincidence, but the definitions of what 403, 404, and 405 end up meaning is something we see as the stories have progressed.
For context, these are the Error Codes, and as the reader I think you may already guess and connect the dots on why I find the correlations so intriguing:
403 Forbidden: Leorio
The request contained valid data and was understood by the server, but the server is refusing action. (Wikipedia) The client does not have access rights to the content; that is, it is unauthorized, so the server is refusing to give the requested resource. Unlike 401 Unauthorized, the client's identity is known to the server... re-authenticating makes no difference. The access is tied to the application logic, such as insufficient rights to a resource. (Mozilla)
404 Not Found: Kurapika (We all know this)
The requested resource could not be found but may be available in the future. Subsequent requests by the client are permissible. (Wikipedia) A 404 status code only indicates that the resource is missing: not whether the absence is temporary or permanent. If a resource is permanently removed, use the 410 (Gone) status instead. (Mozilla)
405 Method Not Allowed: Gon (Though I think the name of the error can speak for itself)
The request method is known by the server but is not supported by the target resource. (Mozilla) A request method is not supported for the requested resource. (Wikipedia)
Further thoughts:
While it's possible that this can definitely be a stretch or a coincidence, it sure is an interesting way to look at it. And even if Togashi did not intend for these to connect, it makes me even more interested to continue reading HxH to see how long they'll connect until they're no longer applicable.
404 interests me because of "temporary unavailable" and "it may be available again in the future", so I wonder if that's applicable not only to Kurapika himself but to the Kurta Clan as well, considering we're entering the Dark Continent and I've already seen a theory on the Kurta Clan originating from the DC one way or another (reddit links)
Think of these as an allegory or metaphor
Mozilla page on HTTP Response Status Codes / Wikipedia page on HTTP Status Codes
#HxH#Hunter x Hunter#HxH Meta#Meta#It's sickening in a way where it makes a lot of sense and it makes me a little sad.#To the point where I don't want to explain the correlation and I'd rather have whoever is reading this make their own connections.#This is so sick and twisted.#While I can even argue about how 401 would 'make more sense for Leorio over 403'-#This post is about 'How their /given/ exam numbers can be tied to them' rather than 'what it ''should'' have been instead'#I hope this makes sense.#Also I am no expert in HTTP and programming or web development- so take what I say with a grain of salt.#I'm speaking in my singlet 'im not a fictive' voice to keep this post coherent... If I had my way I'd just say 'myself' the entire time.#Pikachika#New Talking tag.. Chika being a reference to Chika / Chika Chika (Filipino) Which means to chit-chat or engage in gossip.
36 notes
·
View notes
Text
i was trying to figure out if my local planned parenthood allowed hormone treatments for kids 16+ with parental consent but i like. i kept getting 403 forbidden errors? this was like right after the election here in the us so i honestly thought for like hours that the government might already be trying to fuck with trans kids getting hormones?? but it was just like. the zip code search not working so i just searched by state and that worked but i had a mini heart attack and i was just so so worried all day long :((
3 notes
·
View notes
Note
Was 403 ever not an error/glitch?
2. Also how does 403 perceive himself? Is he confident, hateful or unsure to himself?
3. What does 403 think of most others in the multiverse?
1. I’m.. not sure.
I haven’t worked on his backstory all that much but he seems a lot more ink or swap coded is all i’m gonna say.
2. It changes from time to time.
Usually, or at least on the outside, he is quite confident in his self image but that can easily crumble if he puts his trust in the wrong person. Which is very easy for him to do.
3. He finds most AU’s and outcomes to be charmingly pathetic.
Something he has to protect, they’re all helpless, but also they look fun to hang around. Despite his self-absorbed mindset he has when meeting people, he really wants some friends.
13 notes
·
View notes
Text
📡 LittleBigPlanet 3 PS4 Server Degraded Performance
Monday, August 21st
We are still hearing reports from users about connectivity issues with the official #littlebigplanet servers on PS4. As of Friday, some users (not all), experience:
- Error 403
- Failure loading online content in game

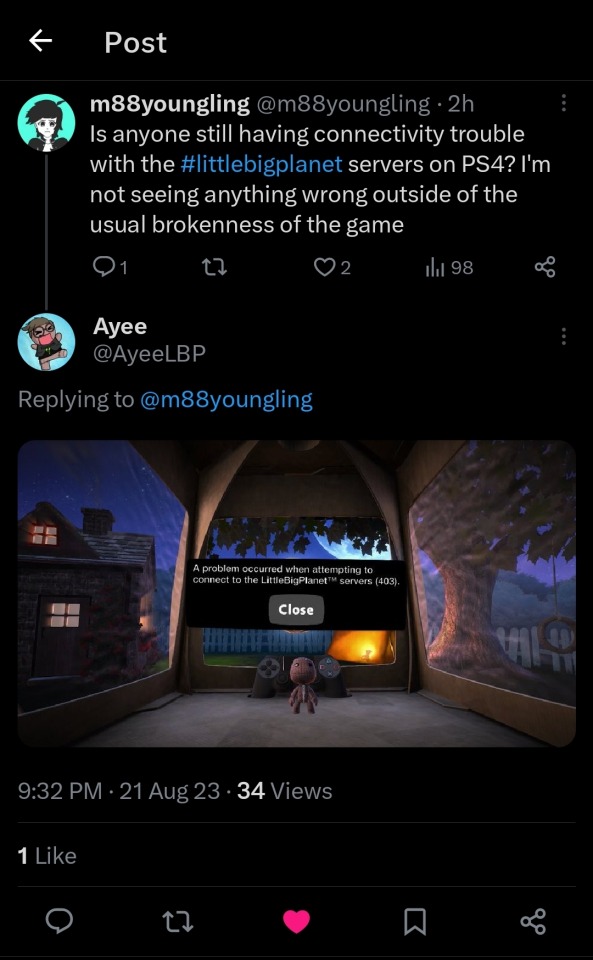
LBP Community Manager Steven Isbell acknowledged the issue on August 19th, explaining that he would ask the team to investigate on Monday.
The status of the investigation is unknown, as users continue to report problems. Popular LBP YouTube Ayee posted a screenshot showing that he is one of the players affected by the recent server issues. The screenshot shows Ayee experiencing a error code 403 when attempting to connect.
Here are some resources to help keep you in the loop about future server status updates:
1. Check out our status page to see the status of official and custom servers.
2. Join our Discord server to get push notifications for major server status changes.
16 notes
·
View notes
Text
Overcoming Bot Detection While Scraping Menu Data from UberEats, DoorDash, and Just Eat
Introduction
In industries where menu data collection is concerned, web scraping would serve very well for us: UberEats, DoorDash, and Just Eat are the some examples. However, websites use very elaborate bot detection methods to stop the automated collection of information. In overcoming these factors, advanced scraping techniques would apply with huge relevance: rotating IPs, headless browsing, CAPTCHA solving, and AI methodology.
This guide will discuss how to bypass bot detection during menu data scraping and all challenges with the best practices for seamless and ethical data extraction.
Understanding Bot Detection on Food Delivery Platforms
1. Common Bot Detection Techniques
Food delivery platforms use various methods to block automated scrapers:
IP Blocking – Detects repeated requests from the same IP and blocks access.
User-Agent Tracking – Identifies and blocks non-human browsing patterns.
CAPTCHA Challenges – Requires solving puzzles to verify human presence.
JavaScript Challenges – Uses scripts to detect bots attempting to load pages without interaction.
Behavioral Analysis – Tracks mouse movements, scrolling, and keystrokes to differentiate bots from humans.
2. Rate Limiting and Request Patterns
Platforms monitor the frequency of requests coming from a specific IP or user session. If a scraper makes too many requests within a short time frame, it triggers rate limiting, causing the scraper to receive 403 Forbidden or 429 Too Many Requests errors.
3. Device Fingerprinting
Many websites use sophisticated techniques to detect unique attributes of a browser and device. This includes screen resolution, installed plugins, and system fonts. If a scraper runs on a known bot signature, it gets flagged.
Techniques to Overcome Bot Detection
1. IP Rotation and Proxy Management
Using a pool of rotating IPs helps avoid detection and blocking.
Use residential proxies instead of data center IPs.
Rotate IPs with each request to simulate different users.
Leverage proxy providers like Bright Data, ScraperAPI, and Smartproxy.
Implement session-based IP switching to maintain persistence.
2. Mimic Human Browsing Behavior
To appear more human-like, scrapers should:
Introduce random time delays between requests.
Use headless browsers like Puppeteer or Playwright to simulate real interactions.
Scroll pages and click elements programmatically to mimic real user behavior.
Randomize mouse movements and keyboard inputs.
Avoid loading pages at robotic speeds; introduce a natural browsing flow.
3. Bypassing CAPTCHA Challenges
Implement automated CAPTCHA-solving services like 2Captcha, Anti-Captcha, or DeathByCaptcha.
Use machine learning models to recognize and solve simple CAPTCHAs.
Avoid triggering CAPTCHAs by limiting request frequency and mimicking human navigation.
Employ AI-based CAPTCHA solvers that use pattern recognition to bypass common challenges.
4. Handling JavaScript-Rendered Content
Use Selenium, Puppeteer, or Playwright to interact with JavaScript-heavy pages.
Extract data directly from network requests instead of parsing the rendered HTML.
Load pages dynamically to prevent detection through static scrapers.
Emulate browser interactions by executing JavaScript code as real users would.
Cache previously scraped data to minimize redundant requests.
5. API-Based Extraction (Where Possible)
Some food delivery platforms offer APIs to access menu data. If available:
Check the official API documentation for pricing and access conditions.
Use API keys responsibly and avoid exceeding rate limits.
Combine API-based and web scraping approaches for optimal efficiency.
6. Using AI for Advanced Scraping
Machine learning models can help scrapers adapt to evolving anti-bot measures by:
Detecting and avoiding honeypots designed to catch bots.
Using natural language processing (NLP) to extract and categorize menu data efficiently.
Predicting changes in website structure to maintain scraper functionality.
Best Practices for Ethical Web Scraping
While overcoming bot detection is necessary, ethical web scraping ensures compliance with legal and industry standards:
Respect Robots.txt – Follow site policies on data access.
Avoid Excessive Requests – Scrape efficiently to prevent server overload.
Use Data Responsibly – Extracted data should be used for legitimate business insights only.
Maintain Transparency – If possible, obtain permission before scraping sensitive data.
Ensure Data Accuracy – Validate extracted data to avoid misleading information.
Challenges and Solutions for Long-Term Scraping Success
1. Managing Dynamic Website Changes
Food delivery platforms frequently update their website structure. Strategies to mitigate this include:
Monitoring website changes with automated UI tests.
Using XPath selectors instead of fixed HTML elements.
Implementing fallback scraping techniques in case of site modifications.
2. Avoiding Account Bans and Detection
If scraping requires logging into an account, prevent bans by:
Using multiple accounts to distribute request loads.
Avoiding excessive logins from the same device or IP.
Randomizing browser fingerprints using tools like Multilogin.
3. Cost Considerations for Large-Scale Scraping
Maintaining an advanced scraping infrastructure can be expensive. Cost optimization strategies include:
Using serverless functions to run scrapers on demand.
Choosing affordable proxy providers that balance performance and cost.
Optimizing scraper efficiency to reduce unnecessary requests.
Future Trends in Web Scraping for Food Delivery Data
As web scraping evolves, new advancements are shaping how businesses collect menu data:
AI-Powered Scrapers – Machine learning models will adapt more efficiently to website changes.
Increased Use of APIs – Companies will increasingly rely on API access instead of web scraping.
Stronger Anti-Scraping Technologies – Platforms will develop more advanced security measures.
Ethical Scraping Frameworks – Legal guidelines and compliance measures will become more standardized.
Conclusion
Uber Eats, DoorDash, and Just Eat represent great challenges for menu data scraping, mainly due to their advanced bot detection systems. Nevertheless, if IP rotation, headless browsing, solutions to CAPTCHA, and JavaScript execution methodologies, augmented with AI tools, are applied, businesses can easily scrape valuable data without incurring the wrath of anti-scraping measures.
If you are an automated and reliable web scraper, CrawlXpert is the solution for you, which specializes in tools and services to extract menu data with efficiency while staying legally and ethically compliant. The right techniques, along with updates on recent trends in web scrapping, will keep the food delivery data collection effort successful long into the foreseeable future.
Know More : https://www.crawlxpert.com/blog/scraping-menu-data-from-ubereats-doordash-and-just-eat
#ScrapingMenuDatafromUberEats#ScrapingMenuDatafromDoorDash#ScrapingMenuDatafromJustEat#ScrapingforFoodDeliveryData
0 notes
Text
How Can You Use Google Search Console to Fix Indexing Issues?

Google Search Console (GSC) is a powerful free tool that helps website owners monitor and troubleshoot their site’s presence in Google Search results. One of its most valuable features is the ability to identify and fix indexing issues. If your pages are not showing up in search results, GSC can guide you to the root of the problem and help get your content back on track.
In this article, we’ll explore the best practices for using Google Search Console effectively to fix indexing issues and improve your site’s visibility.
1. Understand How Google Indexing Works
Before diving into fixes, it’s important to understand the basics. Indexing is the process through which Google crawls web pages and stores them in its database. Only indexed pages are eligible to appear in search results.
Common reasons pages may not be indexed include:
Crawl errors
Duplicate content
Noindex directives
Poor internal linking
Blocked by robots.txt
GSC helps identify these issues so you can take corrective action.
2. Start with the “Index Coverage” Report
The “Index Coverage” report in GSC gives a detailed overview of how your pages are indexed. It categorizes URLs into:
Valid — Pages indexed and working fine
Error — Pages with critical issues preventing indexing
Valid with warnings — Pages indexed but with potential issues
Excluded — Pages intentionally or unintentionally not indexed
Action Tip: Regularly check this report to spot errors like “Submitted URL not found (404)”, “Crawl anomaly”, or “Duplicate, submitted URL not selected as canonical”.
3. Inspect Individual URLs
The URL Inspection Tool allows you to check the status of any page on your website.
To use it:
Paste the URL in the inspection bar
GSC will show if the page is indexed, how it was crawled, and if there are any issues
If not indexed, you’ll get reasons like:
Discovered — currently not indexed
Crawled — currently not indexed
Blocked by robots.txt
Marked ‘noindex’
Action Tip: For pages that should be indexed, click “Request Indexing” after fixing the issues. This tells Google to re-crawl and potentially index your page faster.
4. Check Your Robots.txt and Meta Tags
Sometimes indexing issues stem from a misconfigured robots.txt file or meta tags.
Things to check:
Your robots.txt file doesn’t block important pages or directories
Important pages don’t have a <meta name="robots" content="noindex"> tag
Pages you want indexed are not blocked in sitemap or canonical settings
Action Tip: Use the “robots.txt Tester” in older versions of GSC or check the source code of your page to ensure there’s no noindex tag where it shouldn’t be.
5. Fix Crawl Errors Promptly
GSC flags crawl errors that may prevent your pages from being indexed.
Common errors include:
404 Not Found
403 Forbidden
500 Internal Server Errors
Redirect loops
Action Tip: Fix broken URLs, update internal links, and make sure your server responds correctly to crawl requests. Once fixed, validate the issue in GSC so Google can recheck it.
6. Submit an XML Sitemap
Your sitemap is a guide for search engines to understand your site structure and find new content.
Make sure your sitemap:
Is up to date
Contains only canonical URLs
Is submitted in the “Sitemaps” section of GSC
Action Tip: After submitting, monitor the status of your sitemap in GSC to ensure it’s processed without errors. Resubmit after major content updates.
7. Use Canonical Tags Correctly
Canonical tags tell Google which version of a page is the preferred one, especially helpful when you have duplicate or similar content.
Incorrect canonical tags can lead to unintended exclusion from indexing.
Action Tip: Make sure each page has the correct canonical URL. Avoid self-referencing canonicals on pages you don’t want indexed.
8. Strengthen Internal Linking
A well-structured internal linking strategy helps Google crawl your site more efficiently. If a page isn’t linked from anywhere, Google might not discover or prioritize it.
Action Tip: Add relevant internal links to orphan pages (pages with no incoming internal links), especially from high-authority pages on your site.
9. Check Mobile Usability
With mobile-first indexing, Google primarily uses the mobile version of content for indexing and ranking.
Action Tip: Use the “Mobile Usability” report in GSC to identify issues like small font sizes, clickable elements too close together, or content wider than the screen. Fix these to improve mobile accessibility and indexing potential.
10. Track Fixes with Validation Reports
When you fix an indexing issue, you can click “Validate Fix” in GSC. This triggers Google to re-crawl the affected pages and update their status.
Action Tip: Always monitor the validation progress. If it fails, investigate further and retry.
11. Monitor Performance After Fixes
Once your pages are indexed, head to the “Performance” section in GSC to track:
Clicks
Impressions
CTR (Click-Through Rate)
Average position
Action Tip: Look for upward trends in these metrics after your indexing fixes. This shows your efforts are improving your site’s visibility.
12. Stay Proactive with Alerts
GSC sends email alerts when it detects serious issues. Don’t ignore them. Being proactive can save you from long-term traffic loss.
Action Tip: Enable email notifications and regularly check your GSC dashboard. Schedule weekly reviews to stay ahead of potential indexing problems.
Final Thoughts
Resolving indexing issues might seem complex at first, but with the right tools like Google Search Console, it's much more manageable. From checking individual URLs to submitting sitemaps and addressing crawl errors, each step helps enhance your site’s presence on Google Search.
With regular and thoughtful use, Google Search Console becomes an essential tool in your SEO toolkit.
Need help managing your website’s indexing and SEO performance? The Webstep Digital Marketing Team is here to assist with expert-level support and guidance. Let us help you keep your site running at its best in the search engine world!
0 notes
Note
Hello! I do something similar in order to auto x-post my bookmarked-on-pinboard AO3 fics as recs on tumblr, using IFTTT - it used to be incredibly easy to have them come out formatted nicely but when tumblr switched over to the new post format it fucked it up royally; I'm going to take a look at make.com to see how that works, but what I've been doing with IFTTT is to auto-make text posts instead of link posts, which lets me auto-scrape and include my bookmark tags... with the loss of working hyperlinks, which I have to add manually later. If I figure out anything more effective I'll definitely let you know!
This was a fun journey to go on this morning 😂 /gen
Yeah, most of the tutorials etc. I've seen for stuff like this use IFTTT, and apparently even I tried to use it for something at some point because when I first tried to set up *this* blog, I already had an account over there that was linked to my tumblr. But I was having the formatting issues you mentioned, and for some reason it kept returning a 403 error for the RSS feed, so I looked into other options.
I found make.com on a reddit thread for free workflow automators, and it seemed both easy to use and had relatively out-of-your-face AI options (current bane of my existence is everything under the sun saying it has AI integrations, and I have to figure out if it's the kind of AI I'm mad at that uses boatloads of electricity, or if it's just a regular-degular computer algorithm that's now being marketed as AI to keep up with the current trends). It really does do a lot of beautiful html coding for you; when I found out that it lists all the tags and ratings as hyperlinks to ao3, I was ecstatic.
The thing I have to do manually is add those things as tumblr tags--make will automatically make a tumblr post with certain tags, but I have yet to find a way to make those tags conditional. Since this is an ao3feed for all DBD fic, I can't blanket tag with a ship/characters like ao3feeds for specific ships can. You can put filters on your scenarios in make, though, so I'm hoping I can do some "if--then" filters like "if text contains [x] then add [y] tag"--but I'm not sure that's within the site's capabilities. I need to do some more reading.
Anyway, thanks for looking into it! I really appreciate it!
0 notes
Text
Prevent Subdomain Takeover in Laravel: Risks & Fixes
Introduction
Subdomain takeover is a serious security vulnerability that occurs when an attacker gains control of an unused or misconfigured subdomain. If your Laravel application has improperly removed subdomains or relies on third-party services like GitHub Pages or AWS, it may be at risk. In this blog, we will explore the causes, risks, and how to prevent subdomain takeover in Laravel with practical coding examples.

A compromised subdomain can lead to phishing attacks, malware distribution, and reputational damage. Let’s dive deep into how Laravel developers can safeguard their applications against this threat.
🔍 Related: Check out more cybersecurity insights on our Pentest Testing Corp blog.
What is Subdomain Takeover?
A subdomain takeover happens when a subdomain points to an external service that has been deleted or is no longer in use. Attackers exploit this misconfiguration by registering the service and gaining control over the subdomain.
Common Causes of Subdomain Takeover:
Dangling DNS Records: A CNAME record still points to an external service that is no longer active.
Unused Subdomains: Old test or staging subdomains that are no longer monitored.
Third-Party Services: If a subdomain was linked to GitHub Pages, AWS, or Heroku and the service was removed without updating the DNS settings.
How to Detect a Subdomain Takeover Vulnerability
Before diving into the fixes, let’s first identify if your Laravel application is vulnerable.
Manual Detection Steps:
Check for dangling subdomains: Run the following command in a terminal: nslookup subdomain.example.com If the response shows an unresolved host but still points to an external service, the subdomain may be vulnerable.
Verify the HTTP response: If visiting the subdomain returns a "404 Not Found" or an error stating that the service is unclaimed, it is at risk.
Automated Detection Using Our Free Tool
We recommend scanning your website using our free Website Security Scanner to detect subdomain takeover risks and other security vulnerabilities.
📷 Image 1: Screenshot of our free tool’s webpage:

Screenshot of the free tools webpage where you can access security assessment tools.
How to Prevent Subdomain Takeover in Laravel
Now, let’s secure your Laravel application from subdomain takeover threats.
1. Remove Unused DNS Records
If a subdomain is no longer in use, remove its DNS record from your domain provider.
For example, in Cloudflare DNS, go to: Dashboard → DNS → Remove the unwanted CNAME or A record
2. Claim Third-Party Services Before Deleting
If a subdomain points to GitHub Pages, AWS S3, or Heroku, ensure you delete the service before removing it from your DNS.
Example: If your subdomain points to a GitHub Page, make sure to claim it back before deleting it.
3. Implement a Subdomain Ownership Validation
Modify Laravel’s routes/web.php to prevent unauthorized access:
Route::get('/verify-subdomain', function () { $host = request()->getHost(); $allowedSubdomains = ['app.example.com', 'secure.example.com']; if (!in_array($host, $allowedSubdomains)) { abort(403, 'Unauthorized Subdomain Access'); } return 'Valid Subdomain'; });
This ensures that only predefined subdomains are accessible in your Laravel app.
4. Use Wildcard TLS Certificates
If you manage multiple subdomains, use wildcard SSL certificates to secure them.
Example nginx.conf setup for Laravel apps:
server { listen 443 ssl; server_name *.example.com; ssl_certificate /etc/ssl/certs/example.com.crt; ssl_certificate_key /etc/ssl/private/example.com.key; }
5. Automate Monitoring for Subdomain Takeovers
Set up a cron job to check for unresolved CNAME records:
#!/bin/bash host subdomain.example.com | grep "not found" if [ $? -eq 0 ]; then echo "Potential Subdomain Takeover Risk Detected!" | mail - s "Alert" [email protected] fi
This script will notify administrators if a subdomain becomes vulnerable.
Test Your Subdomain Security
To ensure your Laravel application is secure, use our free Website Security Checker to scan for vulnerabilities.
📷 Image 2: Screenshot of a website vulnerability assessment report generated using our free tool to check website vulnerability:

An Example of a vulnerability assessment report generated with our free tool, providing insights into possible vulnerabilities.
Conclusion
Subdomain takeover is a critical vulnerability that can be easily overlooked. Laravel developers should regularly audit their DNS settings, remove unused subdomains, and enforce proper subdomain validation techniques.
By following the prevention techniques discussed in this blog, you can significantly reduce the risk of subdomain takeover. Stay ahead of attackers by using automated security scans like our Website Security Checker to protect your web assets.
For more security tips and in-depth guides, check out our Pentest Testing Corp blog.
🚀 Stay secure, stay ahead!
1 note
·
View note